Design a Webcrawler
Design Considerations
- Scalability - highly scalable as it would be crawling hundreds of millions of webpages
- Extensibility - modular so that it could be extended easily (http, https, ftp, media etc.)
Scope
- Crawl HTML pages only - media type (images/videos can be supported later)
- Http Protocol - FTP and others could be added later
- Expected number of pages to crawl ~ 15billion
- Robots Exclusion - excludes sites with robots.txt
Capacity
Pages to crawl: 15B
Pages crawled in a sec in 4 weeks: 15 B (4 weeks x 7 days x 86400 secs) ~= 6200 pages / sec
Storage
15B x (100 KB + 500 bytes metadata) = ~ 1.5 petabytes
Operate at 70% capacity model i.e we never go above 70% total storage
1.5 petabytes / 0.7 ~= 2.14 petabytes
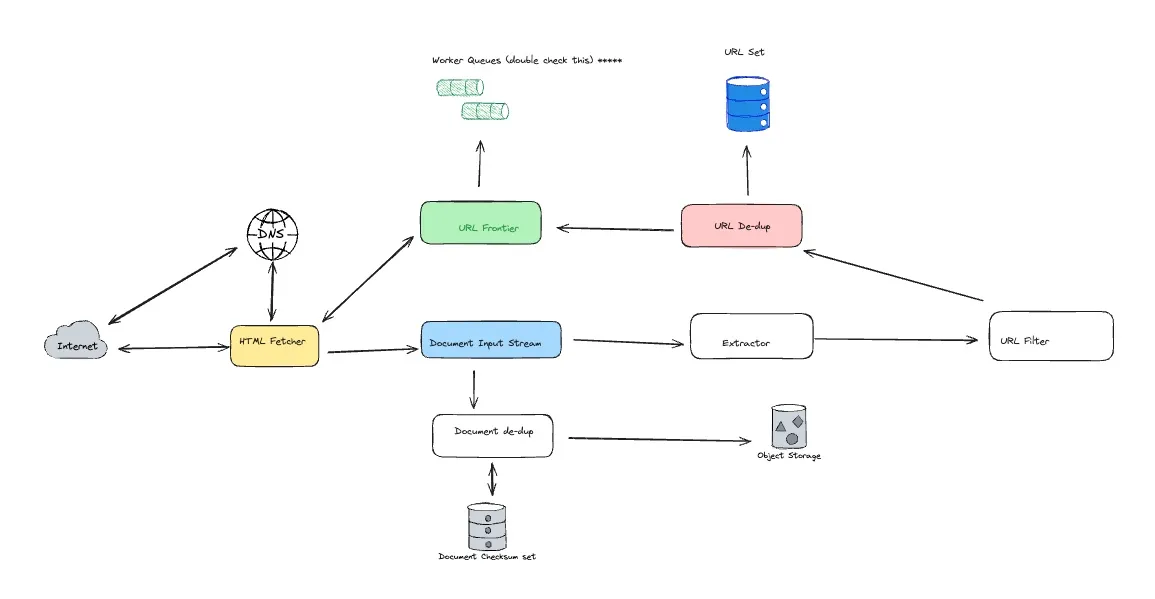
High Level Design
Pick a URl (unvisited) → Resolve IP (DNS lookup) → Establish connection → Parse HTML document → Add new URLs to an unvisited URLs set → Process downloaded document (index) → Repeat
Crawling Strategy
-
Breadth First Search / DFS
- DFS can save handshaking overhead
-
Path-ascending crawling:
- For example, when given a seed URL of http://foo.com/a/b/page.html, it will attempt to crawl /a/b/, /a/, and /.
Challenges
- Large Scale of web pages - should prioritize crawling certain URLs
- Rate of change of web pages: dynamic web pages changing frequently
Components
URL frontier
Store list of URLs to crawl, has set of seed URLs, and prioritizes URLs
HTML Fetcher
Downloads a web pages
Extractor
Parses an HTML document and adds URLs to visit in URL frontier
Duplicate Eliminator
Dedup content that is extracted
Datastore
Store retrieved pages, URLs, and other Metadata
Detailed Component Design
- Muti-threaded approach - each thread performs:
- Remove a URL from URL frontier
- Check protocol (HTTP or HTTPS ..)
- Download the document and add to DIS (Document Input Stream)
- Check for duplicate and remove if duplicate
- Process downloaded document / parsing
- Check MIME Type (HTML, Image, Video etc) → Modular design
- Extract all the links from the HTML page → convert to absolute URL and test against user supplied URL filter and see if it should be downloaded (check visited set) → add to URL frontier
URL frontier
- Distribute frontier into multiple servers
- Each server has worker threads for crawling
- Hash function maps each URL to a server which will be responsible for crawling it
- Multiple machines/crawlers should not connect a web server
- Work stealing algorithm → each server has its own sub-queue
- URL has maps to which server queue a URL should be placed on
- Store URLs on disk → very large size → need a FIFO queue backed by disk → queue can have a buffer backed by disk (cache + disk)
Fetcher module
- Downloads the document for a URL
- To avoid downloading restricted parts (robots.txt), maintain a cache with mapping of rules to host names
Document Input Stream
- Enable the same document to be processed by multiple modules (html, video etc)
- The DIS can cache small documents (64 KB or less) entirely in memory, while larger documents can be temporarily written to a backing file.
- Each worker thread has an associated DIS, which it reuses from document to document. After extracting a URL from the frontier, the worker passes that URL to the relevant protocol module, which initializes the DIS from a network connection to contain the document’s contents. The worker then passes the DIS to all relevant processing modules.
Document Dedupe Test
- Calculate 64 bit checksum of every processed document and store in a database
- MD5 or SHA
- Storage : 15B x 8bytes (120GB)
- Can fit this on a single server but can use LRU Cache backed by persistent storage.
- Check if checksum is in cache, otherwise check database
DNS
- Domain to IP lookup
- Bottleneck → cache results by building a local DNS server to avoid repeated requests for the same URLs
Checkpointing
- Takes weeks to complete
- To guard against failures, crawlers can write a snapshots of its state to the disk which can then be used to restore in case of a failure
Fault Tolerance
- Consistent hashing for distributing load among crawling servers
- Crawling servers will be performing regular checkpointing and storing their FIFO queues to disks
Data Partitioning
- URLs to Visit
- URL Checksum for dedupe
- Document Checksum for dedupe
- Since we are distributing URLs based on the hostnames, we can store these data on the same host. Since we will be using consistent hashing, we can assume that URLs will be redistributed from overloaded hosts.
Crawler Traps
- Spam sites, cloaked content, infinite links
High Level Design